Spark 大数据计算分为两部分,一是资源调度,二是任务调度,可以说这二者贯穿了 Spark 程序运行的始终,因此是十分重要的内容。
资源调度
资源调度根据 spark 启动方式的不同会有 client 和 cluster 两种调度方式。两者的区别主要在于 driver 端的启动位置,client 模式下,driver 会直接在本地启动,而 cluster 模式下 driver 则会在集群中的 ApplicationManager 下启动。此处主要阐述 cluster 模式下资源调度。
client 方式下的资源调度
client 模式下 driver运行在客户端上,此模式可以用来调试,因为所有的日志都会在客户端上打出来,但是这样会造成客户端流量过大
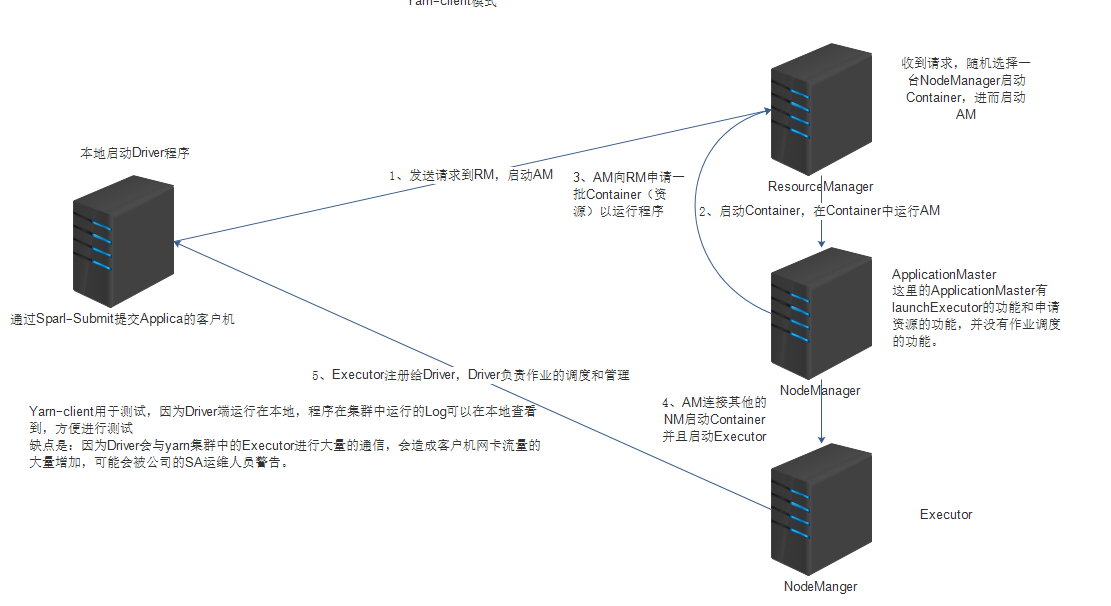
client 模式下的资源调度流程如下:
1.在启动 application 的节点上启动 driver 程序,这里 driver 主要负责任务调度
2.driver 发送任务到 ResourceManage,RM 收到请求后挑选一个节点启动 ApplicationManage
3.AM 向 RM 注册并申请供 AM 使用的 container,申请到 container 后 AM 会对其进行配置,然后连接 NodeManager 启动该节点上 container 中的 executor
4.NM 会将 executor 反向注册给 driver ,以便让 driver 进行任务调度。
cluster 模式下的资源调度
cluster 模式下,客户端在仅起到提交用户程序的作用,程序提交后 driver 将会在 AM 下运行,cluster 多用于生产环境,由于 driver 不在 client 上,故无法看到日志,只能通过 yarn application-logs applicationId 来查看
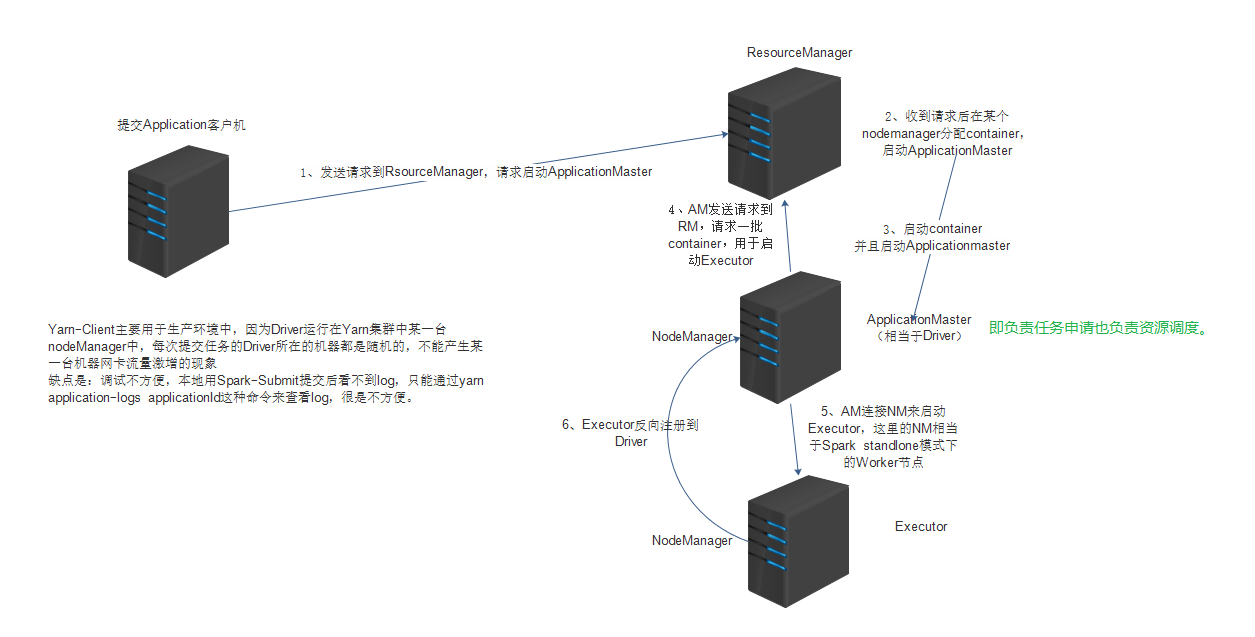
当通过 spark-submit 命令启动一个 spark 应用时,在 cluster 模式下,将会启动 org.apache.spark.deploy.yarn.Client 启动后第一件事是提交一个 yarn 的 application 到 Yarn Resourse Manager(RM) 。详细的说,这个过程包括以下两个部分:
1.从 spark 的库中创建并启动一个 YarnClient 对象
2.调用其中的 createApplication 方法
之后首先从 Yarn 接收 GetNewApplicationResponse 实例对象,然后再判断内存是否足够启动 spark Driver 和 executor,然后创建 ContainerLaunchContext (这里包括了在 NodeManager 中启动容器所需的所有信息)和 ApplicationSubmissionContext(这里包含 RM 为一个 application 启动 ApplicationMaster 所需要的全部信息) 。最后,等待 RM 在第一个分配的容器内启动 AM。
AM 将自己注册到 YarnRMClient 然后返回一个 YarnAllocator 的实例,spark YarnRMClient 其实就是 yarn 的 AMRMClient 的包装类,用来处理使用 yarn RM 来进行 AM 注册和注销的操作。一旦 AM 得到了这个 YarnAllocator ,立刻就会去调用 allocateResources() 方法,这会调用 yarn 的 AMRMClient 去分配所有的容器 。接下来一个重要的事就是启动 ReporterThread 以保持调用 allocateResources() 和 进行一些睡眠操作。对于每个分配成功的容器,将会调用 Allocator 的 runAllocatedContainers() 方法,此方法将会在这个容器内启动 ExecutorRunnable 的实例以启动 executor。
上面已经说了 executor是怎样启动的,那么 spark-yarn 又是怎样管理这些资源的呢?
spark 对资源的调度是通过管理 container 实现的,主要的 container 管理是通过 YarnAllocator 实现的。YarnAllocator 有所有正在运行或已经失败的 executor 的状态,AM 将会定时调用他的 allocateResources() 方法(默认为 200ms,如果 container 数量过多将会需要一个更长时间的睡眠来等待上一个请求完成),YarnAllocator 也会处理 executor 运行位置的问题,也就是决定将供 executor 运行的 container 分发到哪个节点。