本篇文章主要介绍如何利用 python 爬虫爬取知乎指定问题下全部视频,其中关键内容为流式文件下载和 tqdm 的使用。
流程梳理
1.对知乎页面进行分析,找到需要的各个参数的位置
2.找到视频链接并分析链接的请求过程,尝试构造视频请求
3.遍历单个回答内的所有视频
4.分析 Ajax 请求,找到问题下各个回答的链接规律
5.遍历整个问题下的所有回答
实施过程
分析页面元素
页面分析其实都是一些老调重弹,可有可无的东西,可直接跳过
首先确定目标页面
没错,就是他,我这大半天的快乐源泉
接着分析页面元素,主要是要找到视频的直链,以及点赞的数量
审查元素翻了翻,发现了一个很可疑的链接,点了点发现竟然就是视频的直链
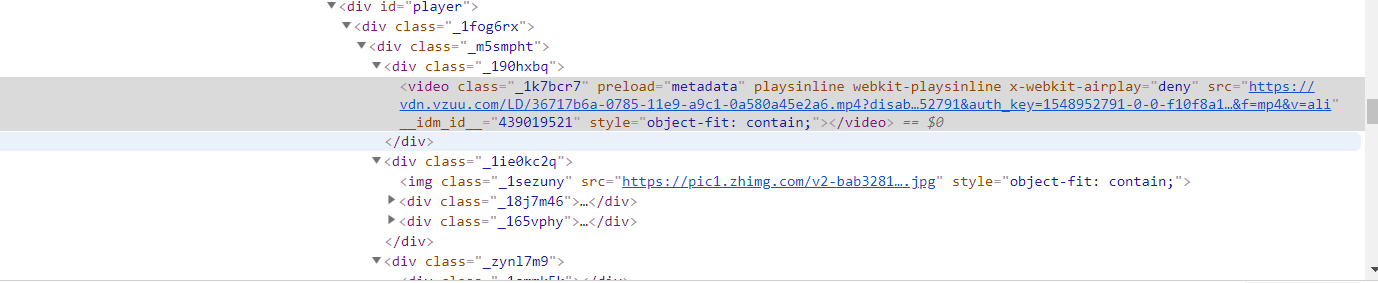
事出反常必有诈,先来构造问题页面的请求看看返回的是不是和审查元素看到的一样的
1 | import requests |
结果返回的数据是这样的

竟然没有回答的内容,果然是套路 
既然请求的数据和页面元素差别很大,那么可以大致推断回答内容是采用异步加载的
打开开发者工具 XHR 选项卡查看 Ajax 请求,然后往下翻页,能看到不停有请求发生,其中能看到一些包含 video 字段的请求链接
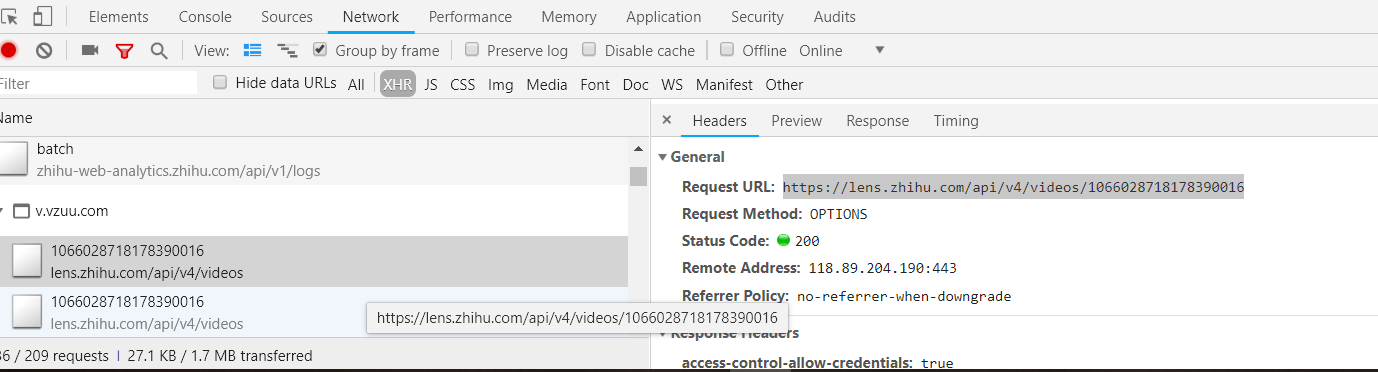
把链接打开返回的是一个多层嵌套的字典,其中 play_url 就是视频的直链

现在回答里的视频链接出处已经找到了,但回答的链接还没找到,向下继续翻了几页,发现了一个链接包含着 answer 字段的请求,点开后发现又是一个超长的嵌套字典,里面包含着一些页面上的内容,不出意外的话这应该就是回答的链接了。

回答页面的请求链接是 https://www.zhihu.com/api/v4/questions/271176530/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=5&offset=10&platform=desktop&sort_by=default 其中最重要的是问题编码,以及 limit 和 offset 字段,问题编码与问题是一一对应的,也就是说可以直接将其他问题的编码代入来进行爬取。limit 是用来限制每次请求返回的回答数量,而 offset 则是用来说明需要请求问题是那些。比如说 limit=5 ,offset=0 就是说要请求第 1-5 条回答
对该地址进行请求并打印返回的内容以及返回的类型,发现返回的内容是字符型不是字典型,于是使用 json.loads() 函数将返回值格式化为字典型。之后在字典中可以提取出总回答数和每篇回答的详细内容,此处也可以使用正则表达式直接提取出所需要的内容,但因为我想要实现根据点赞数来对回答进行区分,所以使用字典对返回的多个答案分别提取。
页面元素的分析到这也就结束了,接下来需要构造请求来下载视频了
视频下载
下载流式文件,requests 中的 stream 设置为 True 就可以了,为什么对于流式文件要单独声明下载方式,这个我有点难以理解,我是这么理解的:当把 stream 设置为 false 时,响应体将会被直接下载,这对于普通小文件来说没有问题,因为伴随着服务器的响应需要的内容差不多也就返回过来了,但对于流式文件来说如果不把文件大小事先告诉程序那么程序是不知道下载应该在何时结束的。而将 stream 设置为 true 时将会推迟响应体的下载,也就是说当使用 r = requests.get(url,stream=True) 时仅有响应头被下载下来了,这时程序可以先获取到文件的大小等相关信息,连接保持开启状态,这就可以在下载时知道文件在什么时候结束,此外这也允许我们根据条件获取内容,例如根据文件大小下载数据,或者是根据文件大小创建一个进度条等等(详见官方文档)。需要注意的是当 stream 设置为 True 时,requests 将不会把连接放回连接池内,除非你消耗完了所有数据,所以在此处必须要让 r 最后 close 以释放连接池。 但在此处又不能使用 with ,with 的原理是在 with 语句体执行前运行 __enter__ 方法,在with语句体执行完后运行 __exit__ 方法,如果语句体内没有这两种方法将不能使用 with ,真坑呐!! 不过这时我们可以使用 contextlib 的 closing 特性,这个特性和函数的装饰器很相似,会自动给函数加上 __enter__() 和 __exit__(),使其满足with的条件,这样就可以使用 with 了。
如此,可写出以下代码:
1 | import requests |
这个代码已经可以实现视频下载的基本功能了,但是还有一些小瑕疵,比如当遇到大文件时会因为内存不足而出错,以及不知道下载进度会让人很难受。现在就开始着手解决这两个问题。
这里就需要介绍两样东西,一个是 requests 里自带的函数 iter_content() ,还有一个是强大的进度条库 tqdm 。
iter_content()
iter_content() 是 requests 库里用于下载块状文件的一个函数,其主要作用是通过指定 chunk_size 参数的大小使每次都下载 chunk_size (单位是B)大小的数据块写入文件,从而有效避免内存不足的问题(网上有人说这里的写入仍然是在内存里,文件下载后才会一起写入文件里,但这样的话我感觉这个函数就没有存在的意义了哇。。)
tqdm
按照其官方文档的说法,tqdm 可用于任何可迭代的对象,可以有以下几种使用方法
1 | from tqdm import tqdm |
其中 trange()是tqdm 和 range 的合体,其等同于 for i in tqdm(range(100)) 。
在这里,tqdm() 是和 iter_content() 一起使用的,iter_content() 将文件分成文件大小( content-length )除以 chunk_size 份,然后迭代遍历
tqdm() 主要用到以下几个参数:
iterable:可迭代对象,也就是你要下载的文件
desc:进度条的前缀
unit:下载速度的单位,默认为 it ( bit )
total:迭代的总次数,这是根据你的 chunk_size 的大小来确定的,比如说你把 chunk_size=1024 ,也就是说每次下载1 k ,那么你的 total 就是 content-lengh/1024 ,同时也要将 unit=’k’ , 以此类推。
以上,就可以推出进阶版的下载代码了
1 | import requests |
下载效果如下
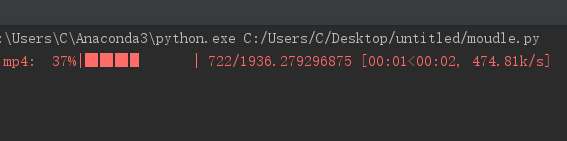
接下来是整个程序的代码,写的有点烂,还有很多地方需要改善
1 | import requests |