本文主要记录 hdfs 中文件的读写过程
写过程
图片说明
文字说明
客户端向 namenode 发出写文件请求
检查是否已存在文件、检查权限。若通过检查,直接先将操作写入 EditLog,并返回输出流对象(DFSOutputStream)
- WAL,write ahead log,先写 Log,再写内存,因为 EditLog 记录的是最新的 HDFS 客户端执行的所有写操作。如果后续真实的写操作失败了,由于在真实写操作之前,操作就被写入 EditLog中了,故 EditLog 中仍会有记录。
DFSOutputStream 将数据分成块,写入 data queue。data queue 由 data streamer 读取,并通知 namenode 分配 datanode,用来存储数据块。分配的 datanode 放在一个 pipline 中。date streamer 将数据块写入 pipline 中的第一个 datanode 并等待成功信息,第一个 datanode 将数据块发送给第二个 datanode 并等待,以此类推。
DFSOutputStream 为发出去的 block 保存了 ack queue,当 pipline 中的所有 datanode 都收到该 block 后,将该 block 从 ack queue 中删除
当客户端结束写入数据,则调用 stream 的 close 函数。此操作将所有的数据写入 pipline 中,并等待 ack queue 返回成功,最后通知元数据节点写入完毕
如果数据节点在写入的过程中失败
首先,关闭 pipline,将 ack queue 中的 block 放入 data queue 的开始以确保 packet 不会丢失
接着,在正常的 datanode 上已保存好的 block 的版本会升级,这样发生故障的 datanode 节点上的 block 数据会在节点恢复正常后被删除,失效节点也会从 pipline 中删除
最后,剩下的数据会被写到 pipline 剩下的节点中
如果 pipline 中的多个节点在写数据时发生失败,那么写成功的 block 数量达到 dfs.replication.min(默认是1),那么任务就是成功的,然后 namenode 将副本数复制达到 dfs.replication 规定的数量(安全模式?)
读过程
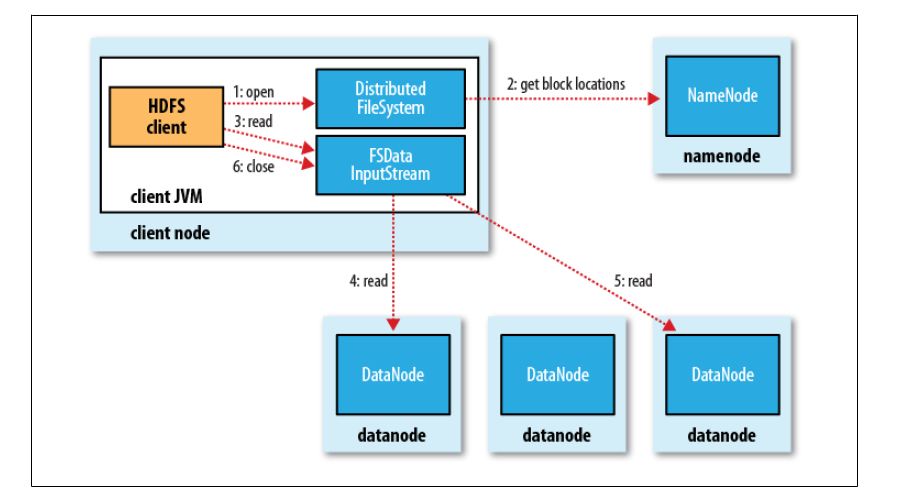
图片说明

文字说明
client 访问 namenode ,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象
就近选择一台 datanode 服务器,请求建立输入流
datanode 向输入流中写数据,以 packet 为单位进行校验(计算 packet 中所有 chunk 的校验和)
关闭输入流